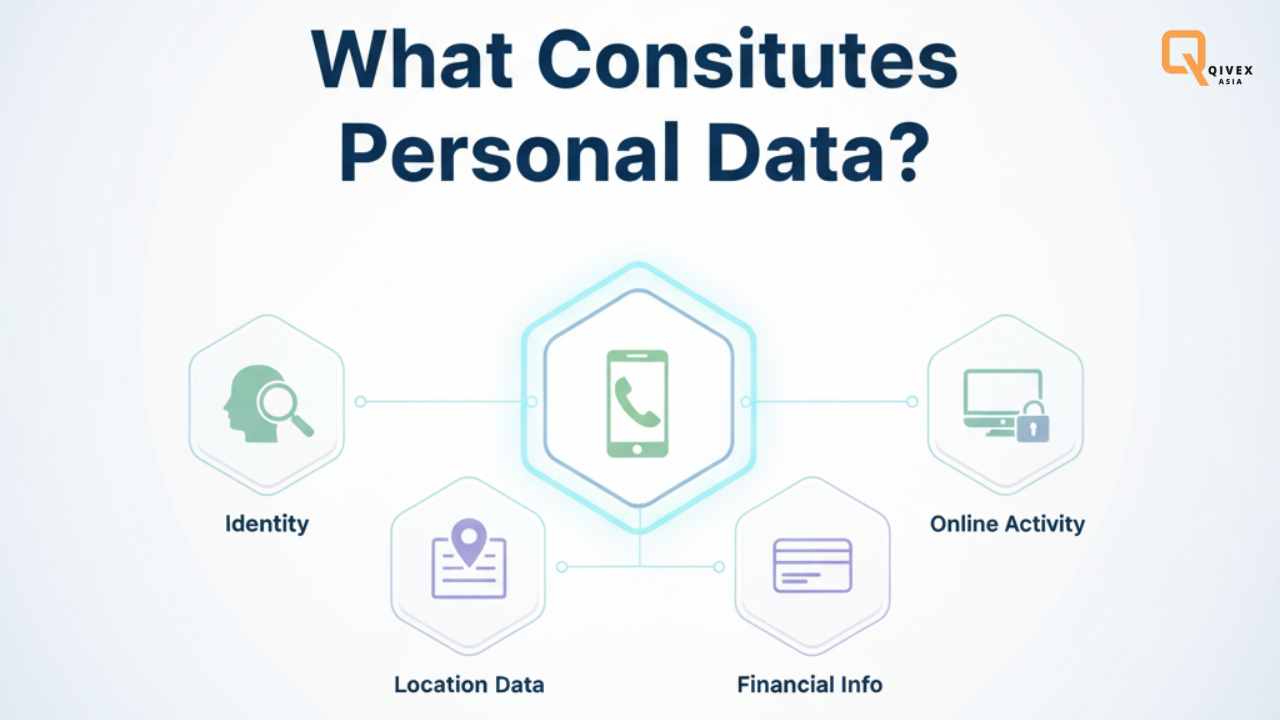
What Constitutes Personal Data? A Detailed Explanation
Shares in privacy-first ad-tech vendors rallied after the UK CMA said Google would keep third-party cookies in Chrome, signaling a pause in the march toward cookieless targeting even as regulators double down on what counts as personal data in digital markets, sources say. In 2024 alone, regulators issued about €1.2 billion in GDPR fines, and the cumulative total since 2018 has reached roughly €5.88 billion, underscoring that definitions aren’t academic; they drive real enforcement and valuation risk for platforms, advertisers, and AI builders alike.
Here’s the thing: a wave of actions from Italy’s Garante against OpenAI to CMA’s oversight of Privacy Sandbox shows that what constitutes personal data is the ballgame for investors, marketers, and engineers.
Google’s April 2025 shift to maintain third-party cookies, while scrapping a standalone user prompt, reopens strategy debates across the open web and highlights how online identifiers, even when “pseudonymous,” can implicate privacy rules and competitive dynamics at scale. Meanwhile, GDPR’s definition remains broad—covering any data relating to an identified or identifiable person—and UK guidance reiterates that pseudonymised data is still personal if linkable, which directly affects ad-tech IDs, IP addresses, and model-training datasets for AI systems.
After cresting the hype cycle for “privacy-safe” ad targeting, reality bites: under GDPR, personal data means any information tied directly or indirectly to a person, which includes cookies, IP addresses, device IDs, and inferences when linkable, while UK regulators stress pseudonymised data remains personal and the CJEU has said dynamic IPs can be personal too. Google’s choice to keep third-party cookies extends the ad-tech status quo, but it doesn’t change the legal floor that treats many so-called anonymous signals as personal data in practice, especially when multiple parties can re-identify or connect dots across systems.
Key Data
Regulators issued about €1.2 billion in GDPR fines across Europe in 2024, bringing the post-2018 total to roughly €5.88 billion, with the largest single penalty being €1.2 billion against Meta in 2023.
The UK CMA confirmed that Google would maintain third-party cookies in Chrome and consulted on releasing prior Privacy Sandbox commitments, reflecting a major policy turn with industry-wide impact.
Italy’s Garante sanctioned OpenAI over ChatGPT’s handling of personal data, reinforcing scrutiny on AI training datasets and legal bases for processing.
Why the Data Matters
Those figures show enforcement isn’t slowing in a meaningful way for data-linked risks, even as platform policies zigzag, which means definitions drive budgets, product roadmaps, and legal exposure across ad-tech and AI.
If cookies remain and identifiers persist, the legal question becomes whether these signals are “personal data” or “pseudonymised personal data,” and under GDPR, that still triggers compliance, security, and rights management duties. The OpenAI case underscores that training on personal data requires a valid legal basis and robust transparency, which reshapes how models ingest web content and user inputs at scale.
What Counts as Personal Data

1. The Legal Core
Under GDPR Article 4(1), personal data means any information relating to an identified or identifiable natural person, which can include names, IDs, location data, online identifiers, or factors specific to identity such as economic or cultural profiles. UK guidance mirrors this and stresses a practical test: if the information relates to an individual and that individual is identified or reasonably identifiable, it’s personal data within scope.
California’s CCPA/CPRA similarly defines personal information as data that identifies, relates to, describes, or could reasonably be linked with a consumer or household, including inferences drawn from other data, which makes the net broad in US consumer law as well. These definitions deliberately avoid technical narrowness, which makes context and linkability the fulcrum of compliance rather than specific field names or static taxonomies.
2. Direct, Indirect, and the IP Address Question
Identifiers are split into direct (name, email) and indirect (cookie IDs, device IDs, or IPs), but the line that matters legally is whether someone can be identified using reasonably available means, including third-party data. The CJEU’s Breyer ruling found that dynamic IP addresses can be personal data where the website operator could, via legal pathways, combine them with ISP-held information to identify users, so treatment depends on real-world identifiability rather than labels alone.
Practical upshot: an IP address in logs isn’t automatically outside scope, especially if the controller or partners could link it, and that affects analytics, security telemetry, and ad delivery workflows across stacks. This smells like the end of “we don’t know their names, so we’re fine,” because linkability, not form, sets the test.
3. Pseudonymisation Versus Anonymisation
UK ICO guidance is explicit: pseudonymisation is a security measure that reduces risk, but pseudonymised data remains personal if it can be re-attributed with additional information, which keeps GDPR obligations in play for many ad IDs and model training corpora. Recitals and definitions make clear that anonymised data lies outside GDPR only when individuals cannot be identified by any reasonably likely means, which is a high bar in modern data ecosystems with rich metadata and auxiliary datasets.
In other words, cookie IDs, mobile advertising identifiers, and hashed emails often remain within scope because linkage keys exist somewhere in the pipeline, even if kept in separate systems under controls. That’s why governance must track data flows and re-identification pathways, not just field labels, when designing privacy by default.
4. Special categories and sensitive signals
GDPR singles out “special categories” like health, biometric, genetic, and political opinions for stricter protections, and those can appear implicitly via inferences, wearable streams, or fine-grained location that reveals sensitive attributes at scale. CPRA adds “sensitive personal information” with obligations to limit use and disclosure, which captures precise geolocation, racial or ethnic origin, and certain financial data within US consumer markets.
In practice, ad segments or model features that infer sexual orientation or health conditions from browsing or app usage will face elevated compliance burdens, including heightened transparency and opt-outs or opt-ins depending on jurisdiction. The trap is that models don’t care about labels, but regulators do, so classification and minimisation must be intentional.
5. Ad-Tech Identifiers and Market Policy
Google’s 2025 move to keep third-party cookies shows consent and user choice remain central, but it doesn’t unwind GDPR’s broad definition that treats online identifiers as personal when linkable, leaving publishers and SSPs squarely within compliance frameworks. CMA’s ongoing oversight of Privacy Sandbox and its consultation on releasing commitments signals a shift from structural cookie changes to competitive neutrality and transparency in how replacement APIs operate and get tested.
For teams planning audience strategies, that means first-party data, clean rooms, and consent orchestration remain critical, even if cookie deprecation is paused, because the legal definition of personal data still catches IDs and event-level telemetry. Here’s the kicker: doing nothing is a strategy only until the next enforcement wave hits.
6. AI Training Data and Legal Basis
Italian regulators’ action against OpenAI centered on processing personal data to train ChatGPT without an adequate legal basis, plus transparency and age-gating concerns, which raises the question of whether web-scraped or user-provided data counts as personal data when models retain patterns or rare strings. Under GDPR, model builders must articulate a lawful basis, provide notice, and respect rights like erasure and access, which becomes operationally complex when vectors or weights encode attributes indirectly but remain linkable back to a person via prompts or provenance.
The ICO’s stance that pseudonymised data remains personal if re-attribution is possible complicates claims that embeddings or hashed identifiers sit outside the scope, because re-linking risk can’t be waved away by math alone. Net result, governance must integrate dataset documentation, opt-out pathways, and retraining or machine unlearning, not just policy pages.
People of Interest
Google’s Privacy Sandbox Lead on Cookie Choice
In April 2025, Anthony Chavez said Google would “maintain our current approach to offering users third-party cookie choice in Chrome” and would not roll out a new standalone prompt, acknowledging divergent views among publishers, developers, regulators, and the ad industry about the impact of cookie changes. That quote matters because it reframes the conversation from outright cookie deprecation to user-controlled settings and iterative API testing, all under the glare of regulators who still see online identifiers as personal data if linkable.
For ad buyers and sellers, this means Privacy Sandbox becomes less of a hard pivot and more of a parallel track, where legal classification of identifiers remains the fire line for risk and measurement. It also puts more weight on consent UX and first-party data pipelines rather than a wholesale identity reset, which keeps compliance directly tied to how identifiers get collected, used, and shared with partners.
Italy’s Garante on AI Training Data
Reuters reported that Italy fined OpenAI for processing users’ personal data to train ChatGPT without an adequate legal basis, and legal analysis highlights requirements to fix transparency, opt-outs, and age-gating as part of remediation, even after a prior suspension was lifted. Lewis Silkin’s summary echoed Garante’s position that training without a clear legal basis and inadequate information duties fell short, requiring both monetary penalties and public communication measures to inform users over time.
In effect, regulators are telling AI firms that training corpora are not a compliance black box; they are personal data pipelines that demand the same discipline as CRM or ad logs, only at a much larger scale. That lesson will reverberate across LLM providers, vector DB vendors, and enterprise adopters who need defensible legal bases for ingestion and reuse, especially where user rights can trigger deletion or model updates.
Looking Ahead
Ad-Tech’s Uneasy Truce
CMA’s consideration to release Google from prior Sandbox commitments is a bellwether that competition authorities may shift focus toward transparency and fair treatment rather than a forced timeline for identifier retirement, but it still leaves publishers and marketers operating under privacy regimes that treat many IDs as personal data. Third-party cookies remain in Chrome, yet ICO guidance ensures that pseudonymised IDs keep compliance obligations in force, so consent, minimisation, and vendor risk management will drive ad spend efficiency as much as audience reach.
Analysts now predict that first-party data strategies and clean rooms will expand faster than wholesale ID replacements, while privacy-respecting measurement becomes a differentiator rather than a commodity checkbox. Not to be cute, but the market has to pick boring, robust governance over silver bullets to avoid the next fine-driven pivot.
AI Governance Grows Up
Expect more cases probing the legal basis for AI training on personal data, with regulators focusing on transparency, opt-out mechanics, and proof that models can honor rights like deletion without degrading safety or accuracy across domains. DLA Piper’s enforcement tallies imply that headline fines may fluctuate year to year, but cumulative pressure keeps climbing, which encourages boards to fund traceable data lineage, model cards, and unlearning workflows tied to identifiable records.
Here’s the thing: if pseudonymised vectors and embeddings can be linked back via reasonable means, they sit inside GDPR scope, and that forces teams to document data sources and manage risk like any other personal data operation. The winners will make privacy-by-design visible in their product and MLOps tooling, not just in glossy policy pages.
Closing Thought
If regulators, platforms, and builders keep redefining the edge of identifiability in practice, will investors price data governance like core infrastructure and force a reset of how products value “anonymous” signals or will the next enforcement cycle do it for them?