
Top 7 Retrieval-Augmented Generation (RAG) Frameworks for Business
Gartner forecasts that global generative AI spending will reach $644 billion in 2025, a 76.4% jump from 2024, even as many internal PoCs under-deliver on promises, which raises the stakes for getting RAG right at scale. At the same time, studies show that RAG reduces hallucinations compared to base models and conventional search, pushing enterprises to anchor outputs in verifiable sources as regulatory pressure and customer trust concerns rise across industries, from healthcare to finance and retail.
Investors want real ROI, IT leaders want reliability, and employees need copilots that cite sources and adapt to workflows without leaking data or adding risk, which is why the winners are now pairing solid retrieval with careful orchestration and governance rather than flashy demos alone.
Here is the thing: RAG is moving from fancy pilot to production muscle because it grounds LLMs in enterprise truth, cuts hallucinations, and gives legal teams something to audit when decisions matter most, even if the hype cycles get loud.
As the spend rises, platforms that blend reliable retrieval, observability, and agent orchestration are taking the lead, which smells like a shift from bespoke stacks toward managed services with clear SLAs and built-in safety rails. Sources say the fastest path to value is a pragmatic mix of proven frameworks and cloud-native RAG services, not a greenfield rebuild, and the seven options below show how to do that step by step.
Key Data
According to McKinsey, generative AI could add the equivalent of $2.6 trillion to $4.4 trillion annually across studied use cases, underscoring why retrieval-grounded deployments are a board-level priority.
Gartner projects worldwide generative AI spending to hit $644 billion in 2025, with hardware absorbing roughly 80% as enterprises scale infrastructure to production workloads.
Peer-reviewed and industry studies show RAG reduces hallucinations and improves out-of-domain generalization versus base LLMs alone, strengthening compliance and user trust in regulated settings.
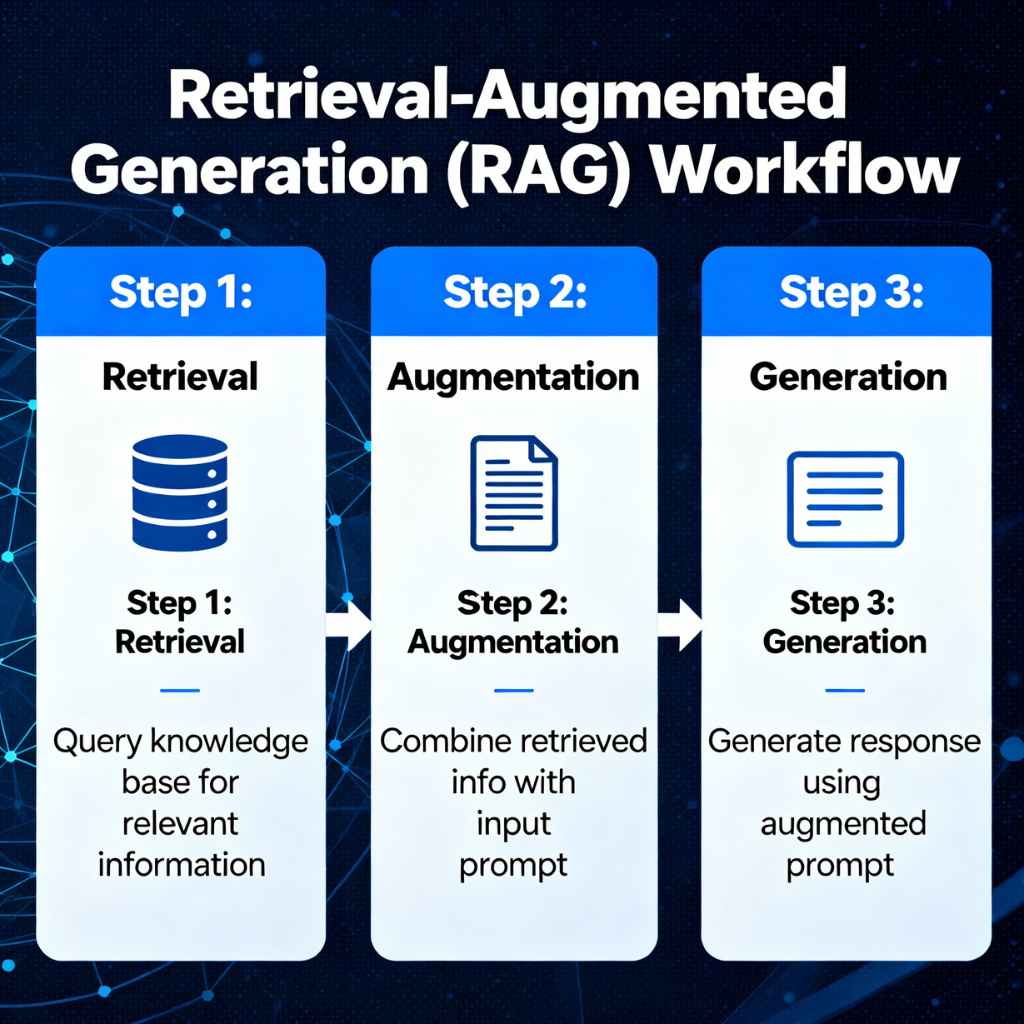
Top 7 Rag Frameworks for Business: Step-By-Step Guide
1. LangChain and LangGraph (with LangSmith)
Why it Matters: LangChain has become a standard toolkit for building LLM workflows, while LangGraph adds controllable, stateful orchestration and long-running agents for production reliability, and LangSmith brings tracing, evaluation, and observability to tighten quality loops.
Step 1 – Model and tools: Start with LangChain integrations for models, vector databases, and external tools so teams can compose retrieval, function calling, and tool use without custom glue code for every provider.
Step 2 – Retrieval and memory: Implement retrieval chains for hybrid search and add structured memory in LangGraph to persist context across turns and workflows, reducing brittle behavior in long conversations.
Step 3 – Orchestration: Use LangGraph to control branching, retries, human-in-the-loop gates, and multi-agent collaboration so agent behavior stays transparent and auditable in production.
Step 4 – Observability: Wire LangSmith for run-level traces, dataset evals, and regression checks to catch degradation early and quantify improvements when changing chunking, embeddings, or reranking.
Step 5 – Deployment: Package agents on LangGraph Platform for enterprise-grade deployment, sharing, and policy enforcement so teams can reuse patterns and guardrails across use cases.
Enterprise Note: Case studies show large vendors adopt the full stack for automation and support workflows, but governance and cost tracking remain key when teams connect many tools quickly.
2. LlamaIndex and LlamaCloud
Why it Matters: LlamaIndex focuses on knowledge assistants over enterprise data with strong parsing, indexing, and retrieval, backed by LlamaCloud for document automation, scaling, and accuracy-centric extraction.
Step 1 – Ingestion: Use LlamaCloud to parse 90+ file types with complex layouts, embedded images, and tables to preserve structure that improves downstream retrieval and grounded answers with citations.
Step 2 – Indexing: Build fit-for-purpose index structures and retrieval strategies per corpus, using modular components to tune chunking, embedding models, and query transforms to the domain.
Step 3 – Retrieval: Enable hybrid retrieval with metadata filtering and confidence scoring, then attach page-level citations so compliance teams can validate answers without manual hunts.
Step 4 – Agents: Compose document agents that can extract, synthesize, and take actions, and measure lift in support accuracy or research throughput with simple metrics tied to tasks.
Step 5 – Scale and pricing: Scale through LlamaCloud tiers and enterprise plans while monitoring volume, latency, and accuracy tradeoffs as document counts reach hundreds of millions.
Enterprise Note: Recognition across enterprise rankings reflects momentum, but leaders still need rigorous evaluations before expanding assistants across departments.
3. Haystack by Deepset
Why it Matters: Haystack is a modular, open framework for agentic, compound AI systems with strong RAG pipelines, extensive vector DB integrations, and a growing focus on production readiness and studio tooling.
Step 1 – Pipeline design: Assemble pipelines for ingestion, embedding, retrieval, and reranking, then add a fallback for dynamic web search when the corpus lacks an answer to improve coverage.
Step 2 – Vector stores: Choose from mature integrations like Qdrant hybrid cloud to meet data sovereignty and security needs while keeping indexing and retrieval latency predictable.
Step 3 – APIs and ops: Expose pipelines as RESTful APIs via Haystack and deepset’s enterprise features to standardize deployment and access across teams and environments.
Step 4 – Tuning: Iterate on chunking, embedding models, and reranking to lift recall and precision for the task, with deepset docs and partner blogs detailing pragmatic optimization patterns.
Step 5 – Agentic extensions: Layer agent capabilities for decision policies that select tools or escalate to humans, keeping policies simple and observable to avoid opaque behavior.
Enterprise Note: Open-source maturity plus enterprise offerings make Haystack a solid anchor for hybrid-cloud RAG with controlled cost and flexibility.
4. Microsoft Semantic Kernel and Azure AI Search
Why it Matters: Semantic Kernel is a model-agnostic SDK for building agents, now converging with Microsoft’s multi-agent stack, while Azure AI Search provides the enterprise retrieval backbone and RAG design patterns at cloud scale.
Step 1 – Retrieval foundation: Start with Azure AI Search’s RAG blueprint to handle chunking, vector, and hybrid search, semantic ranking, and connectors across Microsoft ecosystems.
Step 2 – Agent orchestration: Use Semantic Kernel for skills, planners, and long-running processes, aligning with AutoGen patterns as Microsoft unifies the multi-agent runtime for production.
Step 3 – Experimental RAG agents: Try the Agent RAG features in Semantic Kernel to evaluate multi-agent retrieval workflows, while keeping the label “experimental” in mind for change management.
Step 4 – Enterprise integration: Tie into Microsoft Graph, M365 data, and Azure governance to enforce RBAC, logging, encryption, and eDiscovery across agent actions and outputs.
Step 5 – Scale: Run on Azure’s managed services and apply SK’s process framework to embed AI within business workflows that need state, approvals, and audit trails.
Enterprise Note: This stack is compelling for Microsoft-centric estates that want deep integration plus a clear runway to production agents with policy control.
5. AWS Bedrock Knowledge Bases
Why it Matters: Knowledge Bases is a fully managed RAG capability in Bedrock that handles ingestion, embeddings, indexing, retrieval, grounding, and citations, including options for structured queries via NL-to-SQL.
Step 1 – Ingest: Connect to S3, Salesforce, Confluence, SharePoint, or web crawlers, then let Bedrock manage chunking and embeddings into supported vector stores with mapping back to the original documents.
Step 2 – Retrieval: Use built-in retrieval with reranking and source attribution so answers include citations and confidence, which reduces risk and speeds audits.
Step 3 – Structured data: Enable NL-to-SQL to query data warehouses and transactional stores without moving data, anchoring responses in authoritative records.
Step 4 – Orchestration: Combine Knowledge Bases with Bedrock Agents for tool use and workflows, and leverage prescriptive guidance and workshops for best-practice deployments.
Step 5 – Fast start: Tutorials and videos show a fast path from zero to a working RAG chatbot, useful for proving value while planning deeper integrations.
Enterprise Note: The managed approach lowers undifferentiated heavy lifting, but leaders should still define evaluation harnesses and governance gates per domain.
6. Google Vertex AI Search and Vertex AI RAG Engine
Why it Matters: Vertex AI Search functions as an out-of-the-box RAG and grounding system with Google-grade search, connectors, OCR, vector search, and tuned vertical offerings, while the RAG Engine provides managed orchestration components for bespoke builds.
Step 1 – Quick start: Add a search widget or set up Vertex AI Search as the retrieval backbone, with built-in ETL, OCR, chunking, embeddings, indexing, and summarization pipelines.
Step 2 – Grounding: Use grounded generation and check-grounding APIs so answers cite the enterprise corpus or Google Search when allowed, reducing hallucinations at the edge.
Step 3 – Custom RAG: For deeper control, adopt the Vertex AI RAG Engine to orchestrate retrieval components through managed services while preserving enterprise governance.
Step 4 – Industry tunes: Explore commerce, media, and healthcare modes to accelerate relevance and compliance without heavy custom ranking pipelines from day one.
Step 5 – Scale and govern: Lean on Google’s privacy and governance features while instrumenting evaluation suites to measure accuracy, helpfulness, and latency per use case.
Enterprise Note: This is a fast, opinionated path to “Google-quality” RAG that can still expose APIs for bespoke needs when teams require finer control.
7. NVIDIA NeMo Retriever and NIM Microservices
Why it Matters: NeMo Retriever provides high-accuracy embedders, multimodal extraction, and reranking, while NIM microservices deliver optimized inference for retrieval and LLMs with GPU-accelerated indexing and search, designed for on-prem, cloud, or hybrid.
Step 1 – Data extraction: Use NeMo to ingest text, tables, charts, and images from PDFs at high speed, then de-duplicate and normalize for consistent downstream retrieval quality.
Step 2 – Embeddings and storage: Convert chunks to embeddings with NeMo embedders and store them in GPU-accelerated vector databases via cuVS for faster indexing and search.
Step 3 – Reranking: Add a NeMo reranker to boost precision so the LLM sees the most relevant passages, which is essential in dense corpora with similar content.
Step 4 – Orchestrate with NIM: Deploy embedders, rerankers, and LLMs as NIM microservices to standardize APIs and scale across Kubernetes with strong performance out of the box.
Step 5 – Blueprints: Start from NVIDIA’s RAG blueprint to accelerate implementation and adopt observability, hybrid search, and programmable guardrails from day one.
Enterprise Note: NVIDIA reports first-place retrieval performance on key leaderboards for visual document tasks, which is relevant for enterprises heavy on PDFs and scans.
People of Interest or Benefits
Gartner’s John Lovelock told VentureBeat that “the device market was the biggest surprise” and that by 2027, it will be nearly impossible to find a PC that is not AI-enhanced, which matters because endpoint upgrades and local acceleration can lift RAG latency and user acceptance in daily workflows. Microsoft’s engineering update notes that teams should “choose Semantic Kernel if they’re building agent production applications that need AI capabilities with enterprise-grade support,” signaling a clear maturation path for multi-agent RAG inside regulated estates that want supportable stacks rather than bespoke code.
NVIDIA positions NeMo Retriever microservices as setting “a new standard for enterprise RAG” with top leaderboard marks on ViDoRe and MTEB visual document retrieval, which is a useful barometer for enterprises wrestling with noisy PDFs, contracts, and scanned records. Here is the thing: each of these voices points to the same reality: leadership cares about predictable performance, observability, and clear lines of support when agents touch core data, not just clever prompts, and the market is moving fast to reflect that shift.
Looking Ahead
Gartner’s spending outlook suggests enterprise boards will keep funding generative AI, but the mix will tilt toward grounded systems where retrieval, ranking, and governance are bundled and measurable, not just raw model upgrades, which favors managed RAG stacks with tight SLAs. Google’s Vertex AI Search and RAG Engine, Microsoft’s Azure AI Search plus Semantic Kernel, and AWS Bedrock Knowledge Bases are each narrowing the gap between PoC and production by abstracting ETL, vector search, and grounding checks, which reduces time-to-value and risk, even if teams still need domain-tuned evals.
Meanwhile, NVIDIA’s NIM and NeMo Retriever will likely power low-latency, on-prem, and hybrid RAG for document-heavy shops where data cannot leave secure boundaries, giving CIOs a compliance-friendly path to agentic workflows across departments. The bigger macro point is simple: as McKinsey’s value estimates collide with enterprise reality, the differentiator is no longer who has the fanciest demo but who can prove fewer hallucinations, faster answers, and clear lineage in production audits week after week.
Closing Thought
If RAG becomes the new default interface to enterprise truth, will leaders reward the stacks that can prove accuracy under pressure, or will the next hype cycle distract budgets before the audits arrive?
Comment Us!






